In this technical report, we target generating anthropomorphized personas for LLM-based characters in an online manner, including visual appearance, personality and tones, with only text descriptions. To achieve this, we first leverage the in-context learning capability of LLMs for personality generation by carefully designing a set of system prompts. We then propose two novel concepts: the mixture of voices (MoV) and the mixture of diffusers (MoD) for diverse voice and appearance generation. For MoV, we utilize the text-to-speech (TTS) algorithms with a variety of pre-defined tones and select the most matching one based on the user-provided text description automatically. For MoD, we combine the recent popular text-to-image generation techniques and talking head algorithms to streamline the process of generating talking objects. We termed the whole framework as \emph{ChatAnything}. With it, users could be able to animate anything with any personas that are anthropomorphic using just a few text inputs. However, we have observed that the anthropomorphic objects produced by current popular generative models often go undetected by pre-trained face landmark detectors thus leading to the failure of the face motion generation, even if these faces possess human-like appearances because those images are nearly seen during the training (e.g., OOD samples). To address this issue, we have incorporated pixel-level guidance to infuse human face landmarks during the image generation phase. To benchmark these metrics, we have built an evaluation dataset. Based on it, we verify that the detection rate of the face landmark is significantly increased from 57.0\% to 92.5\% thus allowing automatic face animation based on generated speech content. In the whole process, only texts are needed for the definition of static images and the driving signal.
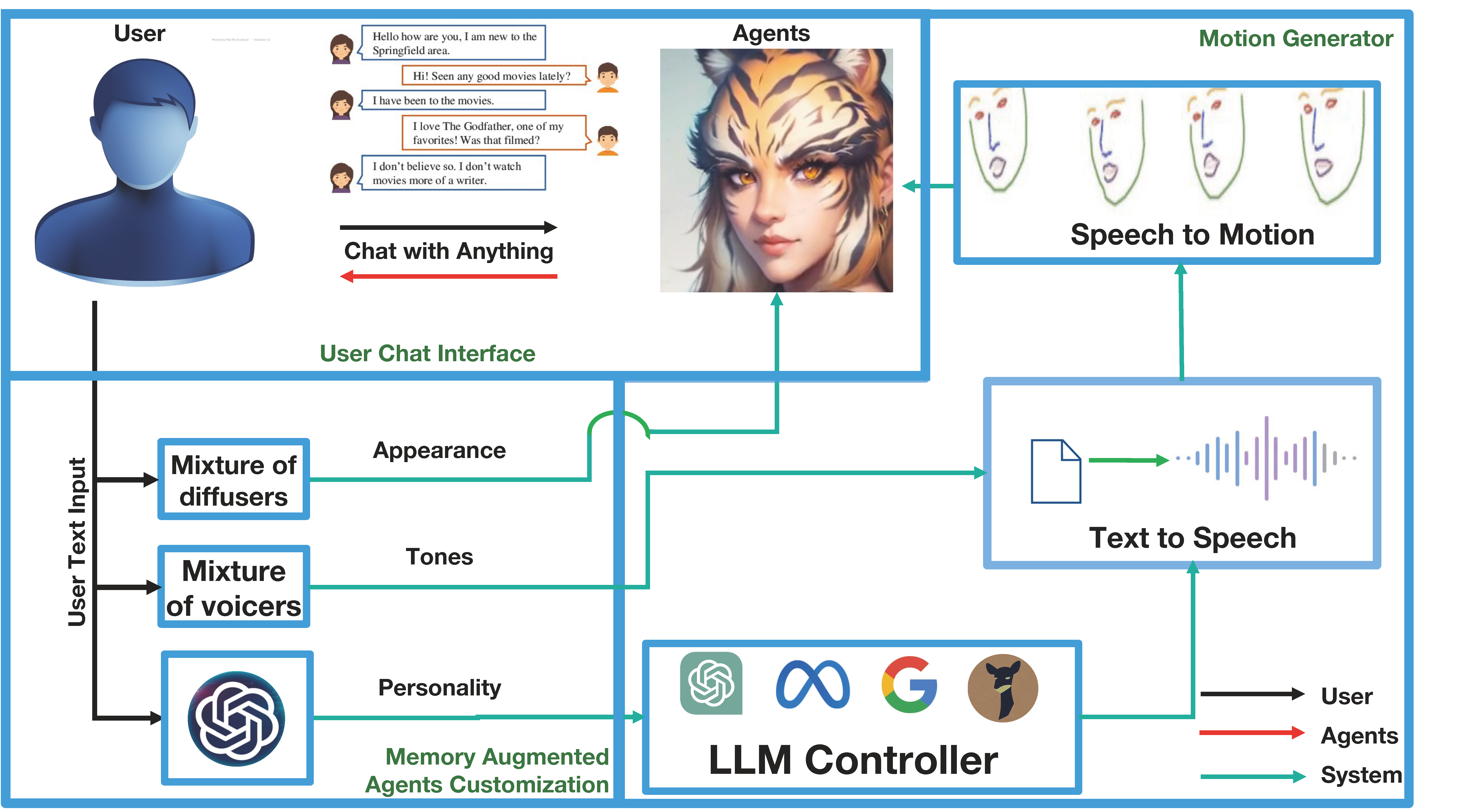
The overall pipeline of ChatAnything. ChatAnything framework includes four key components:
Impact of landmark guidance during the diffusion process. As shown in the first row, directly apply SD1.5 for portrait generation tends to produce abstract face images. Those images are rarely seen during the training of the talking head models and thus cannot be used as the input for facial expression generation. Differently, after applying the proposed techniques in ChatAnything (including the face landmark guidance, prompt engineering, and LoRA fine-tuning for aesthetics improvements), the model tends to generate more anthropomorphic images with high visual quality that can be used as the input for pre-trained talking head models

Adopting a pretrained facial landmark control and diffusion inversion on a human face demonstrates a powerful usage of the finetuned pretrained derivatives of image generative models. This ensures a high aesthetics starting point for the Talking head Chat.
To prompt everything with a simple text input. Multi image generative models and multi TTS Voice are selected by the powerful Language Model. A pretrained generative model will be selected for the initial frame generation. And with the generated frame, a open-source animation module is used for rendering the video base on the audio output of another selected TTS Voice. To start with, here are a grid of faces for animation generated by the pipeline, showing an average expectation of the Imaginary talking face.

We support uploading your own face guidance to the generative model. Also Try out some none face images. There might be a suprise.
@misc{zhao2023ChatAnything,
title={ChatAnything: Facetime Chat with LLM-Enhanced Personas},
author={Yilin, Zhao and Xinbin, Yuan and Shanghua, Gao and Zhijie Lin and Qibin, Hou and Jiashi, Feng and Daquan, Zhou},
publisher={arXiv:2311.06772},
year={2023},
}
The logo is an image generated with "Sichuan Opera with modern elements. Cyberpunk, ultra-modern, futurism, mechanical ascension. Mechanical style, super fantasy, dreamlike fairyland and cyberpunk. Artificial intelligence Sichuan Opera with an internationalist perspective."